Deixa eu começar pelo problema, como sempre gosto de fazer.
O jogo virou: você não contrata mais infra, você aluga tokens
Durante quinze anos a conta era simples. Você queria capacidade? Comprava servidor, dimensionava CPU, memória, storage. A dor era CAPEX. Hoje, quando uma empresa quer colocar IA pra dentro, a pergunta mudou. Ninguém pergunta “quantos núcleos eu preciso”. A pergunta virou “quantos tokens por mês eu vou queimar?”.
E aqui mora a armadilha. Token é o novo aluguel. É bonito no começo, você não compra nada, sobe uma API, paga pelo uso. Mas todo mundo que já passou por isso sabe: o modelo de “pague pelo uso” é maravilhoso até o uso virar rotina. Aí a fatura da OpenAI, da Anthropic ou do provedor da vez começa a subir de forma silenciosa e mensal, igual assinatura de streaming que você esqueceu de cancelar, só que com três zeros a mais.
Gosto de pensar que a IA repetiu o mesmo ciclo da nuvem: primeiro todo mundo migra encantado com o “sem servidor pra gerenciar”, e uns anos depois começa o movimento de trazer carga de volta pra casa porque a conta não fechou. Token é OPEX puro. E OPEX que cresce sem teto é dívida técnica disfarçada de conveniência.
É nesse ponto que o GB10 entra na conversa.
O que é o Dell Pro Max GB10 (e por que ele não é “só mais um mini PC”)

Por baixo do chassi: o NVIDIA GB10 Grace Blackwell Superchip.
Esqueça a aparência. Este tijolinho preto de aparência despretensiosa é, na prática, um supercomputador de IA de mesa. Por baixo do chassi ele carrega o NVIDIA GB10 Grace Blackwell Superchip, e os números fazem você repensar o que “desktop” significa:
- CPU Grace de 20 núcleos Arm (10 Cortex-X925 + 10 Cortex-A725)
- GPU Blackwell com 6.144 núcleos CUDA
- Até 1 PetaFLOP (1.000 TFLOPS) de desempenho em FP4
- 128 GB de memória unificada LPDDR5x CPU e GPU compartilhando o mesmo pool, sem cópia de dados de um lado pro outro
- 273 GB/s de banda de memória
- SSD Gen5 de 4 TB
- NIC ConnectX-7 com par de portas QSFP para 200 Gbit de rede
- Vem com o NVIDIA DGX OS já pronto, drivers, CUDA e frameworks (PyTorch, TensorFlow) pré-configurados

Conectividade: 4x USB-C 20Gbps, HDMI, 10GbE e o par de portas QSFP de 200 Gbit.
Traduzindo o número que mais importa: 128 GB de memória unificada é o que muda tudo. Numa GPU de jogo tradicional, você esbarra nos 12, 16, 24 GB de VRAM e o modelo simplesmente não cabe. Aqui, CPU e GPU bebem da mesma fonte de 128 GB. É por isso que esse aparelhinho aguenta modelos de até 200 bilhões de parâmetros rodando localmente, se você juntar duas unidades pelas portas QSFP, chega a modelos ainda maiores.
O teste: Llama de 8 bilhões de parâmetros, sem tocar na nuvem
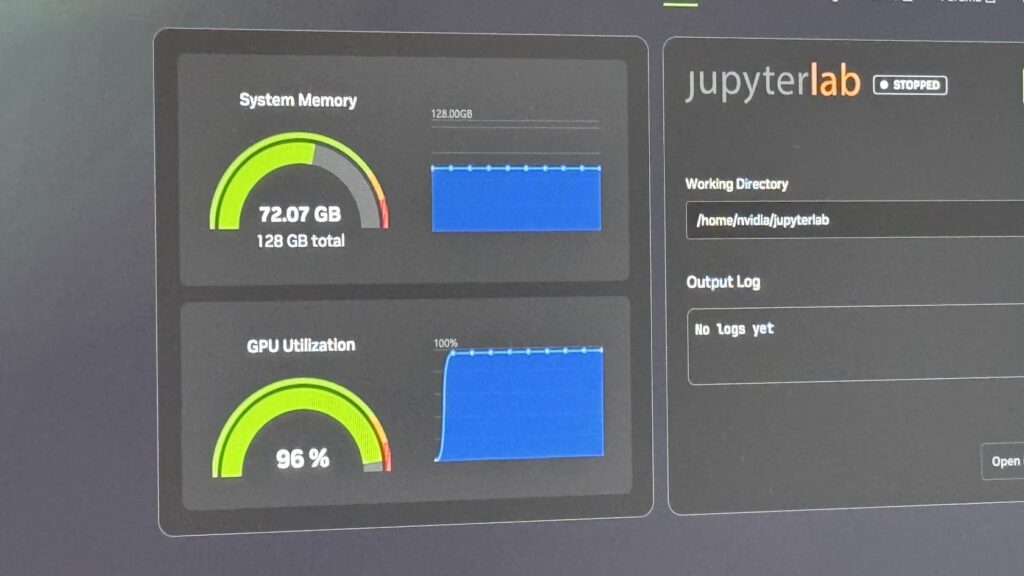
72 GB de memória em uso, GPU cravada em 96%: o hardware sendo realmente exigido.
Foi aqui que a ficha caiu de vez.
Eu não fui o piloto dessa vez, acompanhei dois amigos entusiastas colocando a mão na massa: um DevOps (Jardel) e um Tech Leader (Douglas). E confesso que aprender vendo gente boa operar às vezes rende mais do que fazer sozinho. Eles subiram um Llama de 8 bilhões de parâmetros local, sem depender de nenhuma API externa, e colocaram pra trabalhar.
O painel conta a história sozinho: 72 GB de memória em uso, GPU cravada em 96%. Ou seja, o hardware estava sendo realmente exigido, e ainda sobrava folga na memória pra crescer.
Pare pra pensar no que isso representa na prática:
- Zero tokens gastos. Cada inferência que roda ali é uma inferência que não apareceu na fatura da nuvem.
- Zero dado saindo de casa. Prompt, documento, informação de cliente, nada trafega pra fora. Pra quem lida com LGPD, jurídico ou saúde, isso sozinho já justifica o investimento.
- Latência previsível. Sem depender de fila de API, sem rate limit, sem “modelo indisponível no momento”.
Um Llama de 8B como esse dá conta com sobra de RAG, sumarização, extração de dados, chatbot interno, classificação, apoio a código. É exatamente o feijão com arroz da IA corporativa, e é justamente essa carga repetitiva e de alto volume que mais dói na conta de tokens quando roda na nuvem.
A conta que ninguém faz: CAPEX de uma vez contra OPEX pra sempre
Um aparelho desses custa, arredondando, algo na casa dos US$ 4 mil, uma vez. Compare com o que uma equipe de desenvolvimento ou um produto interno queima em tokens de API rodando dia e noite. Em muitos cenários que já vi, o equipamento se paga em meses, não em anos. Dali pra frente, cada inferência é praticamente de graça, você já pagou pelo hardware.
É a mesma lógica de sempre, só que aplicada a um mundo novo: infraestrutura própria é um custo que você amortiza; token de nuvem é uma torneira que nunca fecha. Não estou dizendo pra abandonar a nuvem, estou dizendo pra parar de usar a Ferrari da API premium pra buscar pão na padaria. A carga de trabalho pesada, sensível e repetitiva desce pra casa. A nuvem fica pro que é de fato eventual, gigante ou de fronteira.
Isso é FinOps aplicado à IA. E FinOps, no fim das contas, é só arquitetura com a calculadora na mão.
E não, isso não é brinquedo de mesa: já tem gente rackeando em datacenter

Esse foi o ponto que mais me surpreendeu na pesquisa.
Muita gente olha pra esse formato de “mini PC” e pensa em uso de mesa, de desenvolvedor. Mas as empresas já entenderam a jogada e estão colocando esses aparelhos dentro do datacenter. Como? Em gavetas (trays) específicas de rack. Já existem kits homologados de rackmount que acomodam duas unidades GB10 em pouco mais de 1U de um rack padrão de 19”, com as portas roteadas pra frente e tudo organizado, e esses kits suportam explicitamente o Dell Pro Max com GB10, além dos equivalentes de Acer, ASUS, GIGABYTE e Lenovo que usam o mesmo superchip.
Ou seja: o que começa como “um teste na mesa de dois amigos” vira, sem drama nenhum, uma fileira de nós de inferência empilhados no rack, cada um servindo seus modelos locais, interligados pelas portas QSFP de 200 Gbit. É um jeito completamente novo de montar capacidade de IA, modular, denso, energeticamente eficiente (o conjunto todo vive de uma fonte USB-C de ~280W) e, principalmente, sem uma fatura de tokens crescendo no fim do mês.
O que eu levo desse teste
O GB10 não vai substituir a nuvem, e nem é essa a proposta. O que ele faz é te devolver uma escolha que a IA-como-serviço tinha tirado da mesa: decidir o que roda dentro de casa e o que vale a pena alugar.
E essa escolha é, no fundo, uma decisão de arquitetura, não de hardware. Quem trata IA só como “assinar uma API” vai descobrir, lá na frente, que terceirizou junto o controle do próprio custo. Quem senta, dimensiona e decide onde cada carga deve viver, continua no comando.
Porque no fim, seja em virtualização, em nuvem ou em IA, o princípio não muda:
A tecnologia mudou o vilão da conta. Mas quem manda na conta continua sendo a arquitetura.
Ficou curioso pra saber se faz sentido trazer inferência pra dentro da sua operação? Me procure — adoro discutir esse tipo de conta.